Die „Verwandtschaft“ wissenschaftlicher Publikationen, könnte der Schlüssel zu besseren Forschungsergebnissen sein. Das Problem der Verwandtschaft wird oft in Recommender Systemen ausgewertet und zum Vorteil der Nutzer aufbereitet. Aus meiner Sicht gibt es hier drei große Arten der Verwandtschaft.
Die direkte Linie
Jede wissenschaftliche Arbeit beinhaltet eine Literaturliste (Bibliografie) in der ein Autor die Vorarbeit anderer Autoren würdigt. Eine unvollständige Literaturliste hat in Deutschland schon so manchem Politiker die Karriere gekostet und wird in wissenschaftlichen Kreisen als inakzeptabel gewertet. Die Literaturliste verrät also unmittelbar die „Großeltern“ (Cited References) eines Dokumentes. Sammelt man diese Literaturlisten über einen längeren Zeitraum, können aber auch die „Kinder“ (Cited By) einer Publikationen gefunden werden.
Diese Methode der „Vorschläge“ nutzen große Zitat-Indexe, wie Web of Science und Scopus, seit vielen Jahren. Aber auch Google Scholar & Microsoft Academic Search binden diese Information ein. Sie ist relativ einfach zu gewinnen und gegen die direkte Linie kann man für Vorschläge nicht viele Argumente bringen. Neben dem Vorschlag relevanter Literatur und der Verknüpfung zwischen Dokumenten, wird diese direkte Linie aber auch oft als Messzahl gewertet und hier finden sich deutlich mehr Kritikpunkte. Dies ist in dem Zusammenhang dieses kurzen Eintrags jedoch nicht wichtig.
Textuelle Analyse
Die Verwandtschaft mehrerer Dokumente kann man jedoch auch auf einer Textanalyse basieren. Sofern eine Datenbank über ein kontrolliertes Vokabular (Thesaurus) erschlossen wird, könnte man allein schon auf diesen Schlagworten Vorschläge zu verwandten Dokumenten treffen. Die Annahme wäre, wenn zwei Dokumente die selben Schlagworte teilen, müssten diese auch über ein sehr ähnliches Thema berichten. Man kann und sollte jedoch noch andere Textelemente einbinden.
PubMed hat so zum Beispiel einen Algorithmus erstellen, der Worte im Titel, Abstract und dem kontrolliertem Vokabular bewertet und dann andere Dokumente ermittelt, die ähnlich aufgestellt sind [1].
Soziale Analyse im Kombination zur textuellen Analyse
Wissenschaftler sammeln Literaturstellen in Literaturverwaltungsprogrammen, wie EndNote, Reference Manager, Zotero, Mendeley, Citavi, RefWorks, etc. Hätte man nun Einblick in diese Literaturlisten, könnte man das gemeinsame Vorkommen bestimmter Quellen in der Bibliothek mehrerer Nutzer also als Verwandtschaftsindikator bewerten – es entstünden Cluster aus Dokumenten als Vorschlagsgrundlage. Man könnte nun davon ausgehen, dass diese Cluster ein Verwandtschaft dokumentieren, die als Vorschlag taugt. Koppelt man dies nun mit einer textuellen Analyse könnten sehr mächtige Vorschläge generiert werden.
Ein anderer Ansatz verfolgen Systeme, bei denen die Nutzungsdaten von LinkResolvern [z.B. bX Recommender] oder Bibliotheskatalogen [z.B. BibTip] ausgewertet werden und zusammen mit einer textuellen Analyse für Vorschläge ausgewertet werden.
Das Problem
Die unterschiedlichen Vorschläge basieren immer auf der verfügbaren Datenbasis.
PubMed.gov erfasst über 23 Millionen Einträge aus der Zeitschriften- und Buchliteratur zum Thema Biomedizin & Lebenswissenschaften (Life Sciences) und verschlagwortet diese mit dem einem kontrollierten Vokabular (MeSH), das so populär ist, dass es weltweit Übersetzungen gibt, die Nutzern die Verwendung erleichtern sollen [2]. PubMed kann somit nur seine eigenen Dokumente für eine textuelle Analyse heranziehen, auch wenn die sehr homogene Datenbasis und das starke und gut angewendete kontrollierte Vokabular zu starken Vorschlägen führt.
Für die direkte Linie muss sich PubMed auf die Daten auf PubMed Central stützen, da man selbst keine zitierten Referenzen pflegt [3].
In Europa gibt es nun auch noch Europe PubMed Central, wo die Inhalte von PubMed & PubMed Central mit anderen Quellen gemischt werden, um noch mehr Informationen für die Nutzer zu finden [4]. Dabei auch die Referenzen aus der Bibliografie eines Artikels (Cited References), sowie ein durch den größeren Inhalt meist größeres Volumen an zitierenden Artikeln (Cited by). Dabei darf man jedoch nicht vergessen, dass die Inhalte in diesen Quellen teils deutlich kleiner sind, als in kommerziellen Zitat-Indices, und somit die Gesamtheit der „cited by“ Information geringer [5].
Mendeley, das vor knapp über einem Jahr von Elsevier – einem der weltweit größten Primärverlagen – gekauft wurde, bietet ebenfalls eine verwandte Dokumente Option, die über deren API genutzt werden kann. Auch wenn es mir nicht möglich ist fest zu bestätigen, in welchem Umfang die soziale Analyse in diese Vorschläge einführen, so wird dieses Vorgehen von Mendeley auf seiner Webseite [6] genannt.
Das eigentliche Problem ist nun, dass keiner dieser Dienste eine Lösung bietet, die alleine auch nur annähernd als umfassend gewertet werden könnte.
Ein Ansatz – MashUp in ein User-Interface
Da mir die Datenberge verwehrt bleiben, die für gute Vorschläge benötigt würden, bleibt mir so nur die APIs von Diensten zu nutzen, um daraus ein hoffentlich einen Mehrwert zu generieren. Im Ende stelle ich also einen kleinen Mashup vor, der mehrere Dienste zu einem zusammenführt. Was ich unter Otzberg.net/pm zusammengestellt habe und mit diesem Artikel kurz vorstellen will, ist also zum einen sehr simplistisch, zum anderen eine nette Spielwiese für mich. Wer mal schauen will, kann hier, hier oder hier passende Beispiele finden.
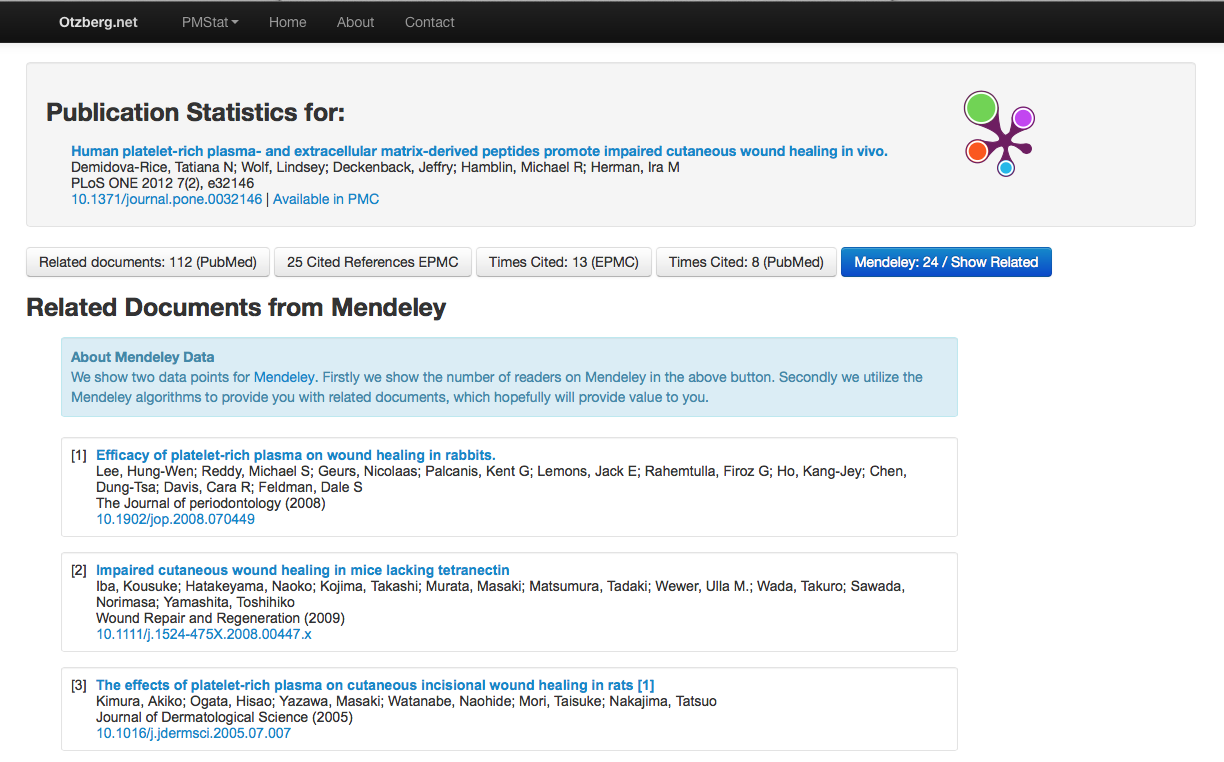
Was ich nun also gemacht habe ist, ein sehr einfaches Front-End zu bauen, welches asynchron die APIs von PubMed, Europe PubMed Central & Mendeley anfragt, um dem Nutzer dann ein „schnelles“ Klicken durch diese Informationen zu bieten. Dabei sollte man sich nicht täuschen lassen – hier findet keine Anreicherung statt, sondern lediglich die Zusammenführung der Informationen aus den APIs mehrerer Anbieter, um dem Nutzer einen Mehrwert zu bieten.
Im Moment kann der Dienst nur auf der Basis einer PMID (PubMed ID) angefragt werden. In Zukunft hoffe ich auch DOI (Digital Object Identifiers) einzubinden. Wer möchte kann auch eine sehr grundlegende Suche in PubMed über AOI absetzen – es werden jedoch immer nur maximal 20 Ergebnisse gezeigt. Ein gutes Recommender System ist dies nun nicht, aber es zeigt dass der Mashup mehrere Quellen deutliche Mehrwerte bieten kann und gibt Anlass sich einmal mehr mit der verfügbaren Datenbasis zu beschäftigen.
Link zum Ausprobieren
Kritik an meinem Mashup
Linda O’Dwyer von der Galter Health Sciences Library der Northwestern University in den USA, hat eine sehr umfangreiche Liste der alternativen PubMed Interfaces zusammengestellt, die für interessierte Nutzer auf jeden Fall interessant sein dürfte [6]. An alternativen, und deutlich besser gemachten Systemen, gibt es also keinen Mangel. Auch diese alternativen Systeme nutzen oft Mashups oder interessante Text Mining Ansätze, um auszeichnete Systeme anzubieten, die im Funktionsumfang und Komfort meiner kleinen Spielwiese jederzeit vorzuziehen wären.
0 Kommentare